Blog
2013-04-21 00:48:14 +0900
このところ暖かい日が続いているなあと思っていたら、急に寒くなって喉の調子を悪くしました。
ところで最近、なぜかSocketからサーバを作る必要があってコードを書いたので、自分の中の整理も含め、JavaでTCPサーバを実装する方法についてまとめたいと思います。
Javaでサーバソケットを扱う
Java SE 7において、サーバソケットを扱う方法は3つあります。
- まずはいわゆる普通のソケットAPIです。JDK1.0の時代からあるAPIで、(つまりこの旧き良きAPIは1996年から存在します) java.net.ServerSocket を使います。
- 次に「ノンブロッキング」と呼ばれるモードで処理を行うAPIがあります。java.nio.channels パッケージにある、ServerSocketChannel と Selector を中心に使います。このAPIはJDK1.4で追加されました。
- そして最後に、非同期で処理を行う最も新しいAPIがあります。これも java.nio.channels パッケージにある、AsynchronousServerSocketChannel を中心に使います。このAPIはJDK1.7で追加されました。
java.net.ServerSocket を使う
最初は基本ということで、私が高校生だった頃には既に活躍していた、普通のソケットAPIを使ってエコーサーバを実装してみましょう。”普通のソケットAPI”と言っても、他のAPIでもソケットの扱い方が違うというだけで、扱うもの自体はあくまで”普通のソケット”には違いないのですが・・・。
これはごくシンプルに書けますので、コードを先に記載します。
try (ServerSocket listener = new ServerSocket();) {
listener.setReuseAddress(true);
listener.bind(new InetSocketAddress(8080));
System.out.println("Server listening on port 8080...");
while (true) {
try (Socket socket = listener.accept();) {
InputStream from = socket.getInputStream();
OutputStream to = socket.getOutputStream();
Bytes.copy(from, to);
}
}
} catch (IOException e) {
e.printStackTrace();
}
順序としてはこうです。
- ServerSocketを作り、ポートにバインドする
- クライアントからの接続を待ち受け(つまりこの ServerSocket#accept() をコールした時点で、スレッドがブロックします)、接続があったらACCEPTしてSocketを得る
- Socketのストリームを使ってアレコレする
- Socketを閉じる
- 以降繰り返し
早速実行してみましょう。
$ java SocketServer
Server listening on port 8080...
これでサーバが起動しました。別のターミナルを開いて接続してみます。
$ telnet localhost 8080
Trying ::1...
Connected to localhost.
Escape character is '^]'.
接続できました。何か入力すれば、入力したものがそのまま出力されてくるはずです。Congratulations! ・・・ただ、このサーバには1つ大きな問題点があります。
スレッド化する
その問題点とは、複数のクライアントからの接続を同時に処理できないということです。ためしに複数のターミナルから接続してみると、1つのクライアントの接続を閉じてからでないと次のクライアントの処理がされないことがわかります。
それというのも、先述のコードではSocketを1つずつしか処理していないからですね。従ってそこをスレッド化しましょう。
ExecutorService worker = Executors.newCachedThreadPool();
try (ServerSocket listener = new ServerSocket();) {
listener.setReuseAddress(true);
listener.bind(new InetSocketAddress(8081));
System.out.println("Server listening on port 8081...");
while (true) {
final Socket socket = listener.accept();
worker.submit(new Runnable() {
@Override
public void run() {
try {
InputStream from = socket.getInputStream();
OutputStream to = socket.getOutputStream();
Bytes.copy(from, to);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
socket.close();
} catch (IOException e) {
}
}
}
});
}
} catch (IOException e) {
e.printStackTrace();
} finally {
worker.shutdown();
}
これで複数の接続を同時に処理できる、極めて実用的なエコーサーバを手にすることができました。
しかしちょっと待ってください、サーバソケットを扱う方法が他にも2つ、あったのでした。それらにはこの”普通のソケットAPI”にはない利点があります(同時に欠点もあるのですが)。次回は2つ目のAPIであるノンブロッキングAPIを使ってみることにしましょう。
2013-04-21 00:48:14 +0900
In these days I feel comfortable Spring, but it has been suddenly very cold from last week. That's why I have a sore throat.
By the way, I don't know why, but I have to implement a server from scratch using sockets recently. So I write about how to implement TCP server in Java, in addition to organizing my ideas.
Handling server sockets in Java
There are three ways to handle server sockets in Java SE 7.
- First, it's what is called "an ordinary socket API". We have had it since JDK 1.0, (or this the good old API have existed since 1996) and it's to use java.net.ServerSocket.
- Second, there is another which handle socket in called "Non-blocking" mode. It's mainly to use ServerSocketChannel and Selector in java.nio.channels package. It's added in JDK 1.4.
- And last, there is the last one which handle socket asynchronously. It's mainly to use AsynchronousServerSocketChannel in java.nio.channels package, too. It's added in JDK 1.7
To use java.net.ServerSocket
At first we should start from basic point. Let's try writing echo-server using ordinary socket API that was already active when I was high school student. Although it's called "ordinary socket API", the others also handle "ordinary socket" but in defferent way.
This API is very simple. See following code.
try (ServerSocket listener = new ServerSocket();) {
listener.setReuseAddress(true);
listener.bind(new InetSocketAddress(8080));
System.out.println("Server listening on port 8080...");
while (true) {
try (Socket socket = listener.accept();) {
InputStream from = socket.getInputStream();
OutputStream to = socket.getOutputStream();
Bytes.copy(from, to);
}
}
} catch (IOException e) {
e.printStackTrace();
}
The proccess is,
- To instantiate a ServerSocket and bind to a port.
- Waiting for an incomming connection from the client, (or the thread is blocked at the method ServerSocket#accept() calling) and obtain a Socket by ACCEPTing the connection.
- To do something over the Socket's streams.
- Closing the Socket.
- Continuing from waiting for new connection.
Then, run this.
$ java SocketServer
Server listening on port 8080...
Good, our server is running. Let's try connecting from another terminal.
$ telnet localhost 8080
Trying ::1...
Connected to localhost.
Escape character is '^]'.
It's OK. Now we have a connection to our server. Input something to the terminal, and get output as is. Congratulations! ...But this server has a big problem.
Multithreading
The problem is that the server can handle only one connection at the same time. To get it, connect from some terminals. The others' connections are not handled unless one's is closed.
That's because we handle a Socket one by one in the previous code. Therefore, we make it multithreaded.
ExecutorService worker = Executors.newCachedThreadPool();
try (ServerSocket listener = new ServerSocket();) {
listener.setReuseAddress(true);
listener.bind(new InetSocketAddress(8081));
System.out.println("Server listening on port 8081...");
while (true) {
final Socket socket = listener.accept();
worker.submit(new Runnable() {
@Override
public void run() {
try {
InputStream from = socket.getInputStream();
OutputStream to = socket.getOutputStream();
Bytes.copy(from, to);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
socket.close();
} catch (IOException e) {
}
}
}
});
}
} catch (IOException e) {
e.printStackTrace();
} finally {
worker.shutdown();
}
It's done. Now we have a very practical echo-server which is able to handle connections at the same time.
Do you have peace of mind? It's too early. Remember that there are the two other ways to handle server sockets. They have some good points which this "ordinary socket API" don't have. (But also have some bad points) Next time, let's check how to use the second, "Non-blocking" API.
2013-02-07 01:28:54 +0900
立春をすぎて、暖かく感じる日も増えてきた今日この頃です。さて春といえばミツバチ、ミツバチといえばHiveですが、今日はHiveを使わないで純粋なMapReduceで、巨大データ同士をJOINするための一つの方法を書き留めたいと思います。
よくある問題
具体的に考えるために、状況を想定してみます。例えば以下の2つのテーブル、アクセスログ(日時,ユーザID,アクセスURL)とユーザマスタ(ユーザID,年齢,性別,住所)があるとします。これらのテーブルをユーザIDで結合したいとしましょう。

SQLで言えば次のような処理ということになります。
SELECT *
FROM access_log
LEFT OUTER JOIN user
USING (user_id);
つまり何ということはない普通のJOINなのですが、この2つのデータがとても大きなものであるとき、私たちは問題に直面します。
解
このようなとき、まず思い浮かぶのはHiveを使うことです。SQLに慣れているならば、極めて直感的に処理を書くことができます。(先述のSQLを書くだけです)
ただしHiveを使わず、純粋なMapReduceを書いて処理したいこともあるでしょう。その場合次の図に示すような手順が考えられます。ここでは3つのMapReduceを使います。
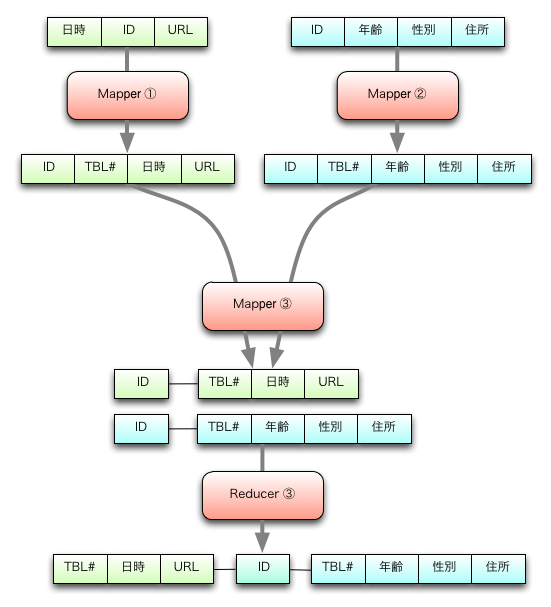
- まず1つ目のMapReduceは、アクセスログを入力とします。Mapperでレコードに含まれているユーザIDを取り出し、テーブル番号(0)と共にレコードの先頭に追加して出力します。Reducerは不要です。
- 2つ目のMapReduceも、ユーザマスタを入力として1つ目と似た処理を行います。即ち、MapperでユーザマスタのレコードからユーザIDを取り出し、テーブル番号(1)と共にレコードの先頭に追加して出力します。これもやはりReducerは不要です。
- 3つ目のMapReduceは、1つ目と2つ目の出力を入力として使用します。Mapperでは、入力をほぼそのまま、ユーザIDをキーとして出力します。Reducerでは、ユーザIDでグルーピングされたレコードを受け取り、先の処理で追加したテーブル番号0のレコードと、テーブル番号1のレコードとを繋ぎ合わせて出力します。
- これでアクセスログとユーザマスタの結合ができました。
重要なことは、3つ目のMapReduceでレコードを識別するために、予め「テーブル番号」を追加しておくということです。今回は0と1を使用していますが、テーブル一意であればもちろん番号でなくても構いません。
2013-01-06 02:35:37 +0900
新年明けましておめでとうございます。今年もよろしくお願いいたします。私は今回の年末年始のお休みの間、なるだけPCを開かないでおこうと心に決めていたのですが、前々から気になっていたHerokuを少しだけ触ってみようかな、などど思い立ってしまいました。
さて、HerokuにはJava・Ruby on Rails・Python/Djangoなど、いくつかのWebアプリケーション実行環境が用意されています。JavaのWebアプリケーションを実行するために、Herokuの公式ドキュメントではJettyを使用していますが、ここはGlassfishを動作させてみましょう。jarファイル1個で起動できるEmbedded Glassfishを使用します。
プロジェクトを作成してローカル環境で実行する
Mavenを使ってビルドを行いますので、まずはpom.xmlを作成します。packagingはwarとし、maven-war-pluginには以下のようにweb.xml不要の設定をします。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<configuration>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
さらに以下のdependencyを追加します。
<dependency>
<groupId>org.glassfish.main.extras</groupId>
<artifactId>glassfish-embedded-all</artifactId>
<version>3.1.2.2</version>
</dependency>
次にGlassfishを起動するクラスを作成します。リッスンポートは環境変数から取得するように設定しています。
public class Bootstrap {
public static void main(String[] args) {
try {
GlassFishProperties gfProps = new GlassFishProperties();
gfProps.setPort("http-listener",
Integer.parseInt(System.getenv("PORT")));
final GlassFish glassfish = GlassFishRuntime.bootstrap()
.newGlassFish(gfProps);
glassfish.start();
ScatteredArchive war = new ScatteredArchive("myApp",
ScatteredArchive.Type.WAR, new File("src/main/webapp"));
war.addClassPath(new File("target/classes"));
glassfish.getDeployer().deploy(war.toURI());
Runtime.getRuntime().addShutdownHook(new Thread(){
@Override
public void run() {
try {
System.out.println(glassfish + " shutdown now!!");
glassfish.dispose();
} catch (GlassFishException e) {
e.printStackTrace();
}
}
});
} catch (GlassFishException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
続いて、基本ということでサーブレットを作成しましょう。
@WebServlet(name = "MyServlet", urlPatterns = "/MyServlet")
public class MyServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req,
HttpServletResponse resp)
throws ServletException, IOException {
PrintWriter out = resp.getWriter();
out.println("Hello, Embedded-Glassfish!!");
}
@Override
public void init() throws ServletException {
System.out.println("init: " + this);
}
@Override
public void destroy() {
System.out.println("destroy: " + this);
}
}
一度ローカル環境でビルドして実行してみます。(クラスパス中、sample-projectの部分は適宜読み替えてください)
$ mvn clean package
$ export PORT=18080
$ java -cp "target/classes:target/sample-project/WEB-INF/lib/*" Bootstrap
うまく起動できたら、別のコンソールを開いてサーバの応答を確認します。
$ curl "http://localhost:18080/myApp/MyServlet"
Hello, Embedded-Glassfish!!
Heroku上で実行する
Herokuで稼働させるためには、もう1つファイルを追加する必要があります。プロジェクトのディレクトリ直下に"Procfile"という名前のテキストファイルを作成し、先ほどのjavaコマンドを記載します。
web: java -cp target/classes:target/sample-project/WEB-INF/lib/* Bootstrap
また、これは必須ではありませんがJDKのバージョンを指定したいときには、これもプロジェクトのディレクトリ直下、"system.properties"ファイルに以下の内容を記載します。
java.runtime.version=1.7
これで設定はできました。後はGitにcommitし、Herokuアプリケーションとしてpushするだけです。
$ git init
$ git add .
$ git commit -m "init"
$ heroku create
$ git push heroku master
pushすると、Heroku側でビルドが行われてアプリケーションが起動します。起動に成功していれば、コンソールに"http://xxxx-yyyy-8888.herokuapp.com deployed to Heroku"といった表示がされていますので、そのURLにアクセスしてみましょう。
$ curl "http://xxxx-yyyy-8888.herokuapp.com/myApp/MyServlet"
Hello, Embedded-Glassfish!!
うまく動作しました。続けて何かを試してみる場合は、commitとpushを繰り返していけばプロジェクトの再ビルドとアプリケーションの再起動が行われます。使い終わったらアプリケーションを破棄します。
$ heroku destroy xxxx-yyyy-8888
深くは突っ込んでいないのですが、EJBやCDI、JSFも試してみた限り問題無く動作するようです(JPAは未確認)。ただし、どの程度の規模のアプリケーションまで正常稼働するのかはわかりません。もともとHeroku自体が軽量なWebアプリケーションをスケールして稼働させるものなので、あまり大掛かりなアプリケーションは載せようとしない方が良いとは思います。
2012-12-27 23:23:15 +0900
Garbage Collection (GC) についての勉強会を行いました。その資料を公開します。
http://www.slideshare.net/akirakoyasu/garbage-collection-for-dummies
内容は以下の通りです。
- JVM & GC - JVMのヒープとGCの基本
- heap in JVM
- Garbage Collection
- stop the world
- Generational GC
- Collectors in HotSpot JVM - HotSpot JVMが備えるGCを総ざらい
- throughput & low-latency
- 5 Collectors
- Ergonomics & Tuning - エルゴノミクスとGCチューニング初めの一歩
- Ergonomics
- JVM options
- command line tools