MapReduceで巨大データ同士をJOINする
立春をすぎて、暖かく感じる日も増えてきた今日この頃です。さて春といえばミツバチ、ミツバチといえばHiveですが、今日はHiveを使わないで純粋なMapReduceで、巨大データ同士をJOINするための一つの方法を書き留めたいと思います。
よくある問題
具体的に考えるために、状況を想定してみます。例えば以下の2つのテーブル、アクセスログ(日時,ユーザID,アクセスURL)とユーザマスタ(ユーザID,年齢,性別,住所)があるとします。これらのテーブルをユーザIDで結合したいとしましょう。

SQLで言えば次のような処理ということになります。
SELECT * FROM access_log LEFT OUTER JOIN user USING (user_id);
つまり何ということはない普通のJOINなのですが、この2つのデータがとても大きなものであるとき、私たちは問題に直面します。
解
このようなとき、まず思い浮かぶのはHiveを使うことです。SQLに慣れているならば、極めて直感的に処理を書くことができます。(先述のSQLを書くだけです)
ただしHiveを使わず、純粋なMapReduceを書いて処理したいこともあるでしょう。その場合次の図に示すような手順が考えられます。ここでは3つのMapReduceを使います。
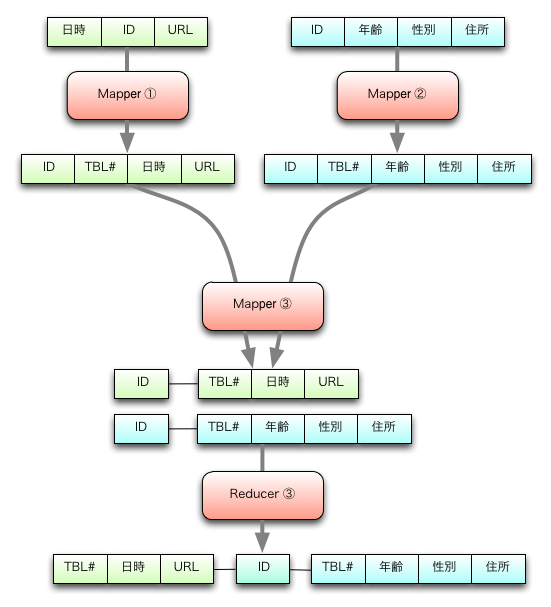
- まず1つ目のMapReduceは、アクセスログを入力とします。Mapperでレコードに含まれているユーザIDを取り出し、テーブル番号(0)と共にレコードの先頭に追加して出力します。Reducerは不要です。
- 2つ目のMapReduceも、ユーザマスタを入力として1つ目と似た処理を行います。即ち、MapperでユーザマスタのレコードからユーザIDを取り出し、テーブル番号(1)と共にレコードの先頭に追加して出力します。これもやはりReducerは不要です。
- 3つ目のMapReduceは、1つ目と2つ目の出力を入力として使用します。Mapperでは、入力をほぼそのまま、ユーザIDをキーとして出力します。Reducerでは、ユーザIDでグルーピングされたレコードを受け取り、先の処理で追加したテーブル番号0のレコードと、テーブル番号1のレコードとを繋ぎ合わせて出力します。
- これでアクセスログとユーザマスタの結合ができました。
重要なことは、3つ目のMapReduceでレコードを識別するために、予め「テーブル番号」を追加しておくということです。今回は0と1を使用していますが、テーブル一意であればもちろん番号でなくても構いません。